
Autonomy with Guardrails: Threat Modeling Agentic AI from Theory to Execution
The recent Five Eyes advisory warns that agentic AI violently expands your attack surface by granting LLMs execution privileges. This guide synthesizes their guidance with OWASP and MITRE, detailing how to apply focused threat modeling and mechanical authorization gates to secure autonomous workflows before they hit production.
Ron Brash
Author
The May 2026 guidance from the ACSC, CISA, and the NSA on the careful adoption of agentic AI services hits the nail on the head: the moment we shift from generative AI to agentic AI, the attack surface violently expands. Its no longer just a chatbot returning text (although a certain airline learnt a lesson here and the world watched); we are integrating LLMs with external tools, memory bases, and execution privileges. But to do this - you have to threat model and understand your impact/exposure. After all - don't shoot the messenger, even the agencies concur.

So when designing defenses for critical infrastructure or interconnected technology, and cobbling together fragmented checklists from disparate frameworks - professionals and architects should understand - many planned defenses and controls will not survive a determined adversary, or an ordinary FDA premarket submission either. Agentic systems actively want to execute actions, which means we must synthesize authoritative guidance from OWASP LLM Top 10 , OWASP Agentic Application Top 10, and ETSI EN 304 223, to MITRE ATLAS - into a coherent reality.
This is exactly where the value of threat modeling shines; it can facilitate “bad day” planning by forcing us out of the theoretical and into the trenches, mapping data flows, defining trust boundaries, and addressing indirect prompt injections before they ever touch production. But with AI – does this hold true? Well – yes, but it means stepping back to do some real engineering to manage the issues that come with it (remember short term gains, often become long-term costs).
From a high - level perspective, here is one take on how you can prepare your architecture, followed by how this plays out in real - world scenarios.
Getting Started: 10 Steps to Prepare for Agentic AI Threat Modeling
1. Define the Approach and Getting Started
Start with a proven, general threat modeling method rather than a niche AI - only framework. For this document’s System under Consideration (SuC), the priority is to build a clear, repeatable way to examine how agentic AI crosses trust boundaries, moves data, invokes tools, and affects downstream systems.
Use a standard approach - such as the Microsoft threat modeling method or another mature framework that helps you reason systematically about assets, actors, trust boundaries, and data flows.
Anchor the exercise - using the artifacts discussed throughout this document, especially Data Flow Diagrams (DFDs), architecture diagrams, API integrations, identity paths, and execution privileges.
Apply the method consistently - across the full agentic workflow: user input, retrieved context, model planning, memory use, orchestration logic, tool calls, and external system actions.
Keep the model practical - the goal is not to chase every edge case, but to create a defensible baseline for analyzing AI - specific risks such as indirect prompt injection, excessive agency, sensitive data exposure, and privilege misuse.
2. Determine Your Security Appetite and Requirements
Before reviewing the architecture in detail, define the security posture for the SuC:
Your risk tolerance,
Compliance obligations,
Liability boundaries,
And consequences of failure or unintended operation.
As the rest of this document makes clear, agentic AI is not just generating content; it is crossing trust boundaries, consuming retrieved context, invoking tools, and potentially acting in downstream systems. That means you should begin with low-risk, non-sensitive use cases and explicitly set the limits for autonomy, data access, execution privileges, performance, auditability, and acceptable blast radius before a single agent reaches production.
3. Assemble the Right Team
You need a team that understands the SuC architecture. This is not just a job for data scientists; it also requires engineers, network architects, and platform owners who can examine how the AI agent will interact with legacy systems and interfaces.
If you simply vibe-code an application without engineering and validating the supporting systems, you may end up with the auditor, tester, and developer all acting as the same person. That is rarely a clever idea, but multiple digital workers may very well be a way through this if you are ready.
4. Gather the Necessary Documents
You cannot model an invisible system. Come to the table with comprehensive data: DFDs, Software Bill of Materials (SBOMs), AI Bill of Materials (AIBOMS), infrastructure as code files, architecture documents, third-party component registries, and explicit API integration specs for every tool the agent can access.
If technical documentation or highly detailed internal specifications do not exist, start with app-notes, product brochures, user-guides, market certifications, and similar documents - most of these can help at least define situations where an attacker may get in, interfaces, external interactions, where AI is used and by what, and at least - the intended operational conditions and situations.
5. Map the Agentic Triggers and Actions
Map, in precise terms, what events, inputs, approvals, or environmental conditions allow the agent to act, and document the exact permissions, tools, and downstream systems it can access at each step. As with the rest of this threat model:
Trace, map, and follow the full data and decision path from user input and retrieved context through LLM planning,
Track and estimate memory use, tokens, persistent artifacts,
Consider any orchestration logic to external tool execution,
Verify where trust boundaries are crossed and what guardrails apply.
This gives you a clear basis for analyzing excessive agency, indirect prompt injection, privilege misuse, and unauthorized actions before they reach production.
6. Apply Model Systematically to the SuC
To effectively secure an agentic AI system, you cannot treat it as a black box. You must systematically walk through your SuC analyzing the user interface(s), data processing, and transformation layers, schema validation, orchestration layer, model runtime, memory stores, retrieval pipelines, and external tools - using a structured framework like STRIDE.
Because agents actively plan, call external tools, and act on context, classic threats manifest in unique, AI-specific ways. Here is one way to apply STRIDE to your architecture, mapped to the OWASP LLM Top 10 and MITRE ATLAS:
Spoofing (Identity & Authenticity):
Agent Context: An adversary tricks the agent into believing a malicious external source is a trusted user or system component.
AI Specific Threat: Indirect Prompt Injection (OWASP LLM01) / Prompt Injection (MITRE ATLAS AML.T0054). An attacker embeds hidden instructions on a webpage or within a document the agent retrieves. The agent reads this context and executes the malicious instructions, spoofing the original user's intent.
Defense Focus: Strict input validation, parsing user prompts separately from external context (e.g., using "ChatML" role definitions), and cryptographic verification of external data sources.
Tampering (Integrity):
Agent Context: An attacker alters the data the AI relies on, changing its reasoning or behavior.
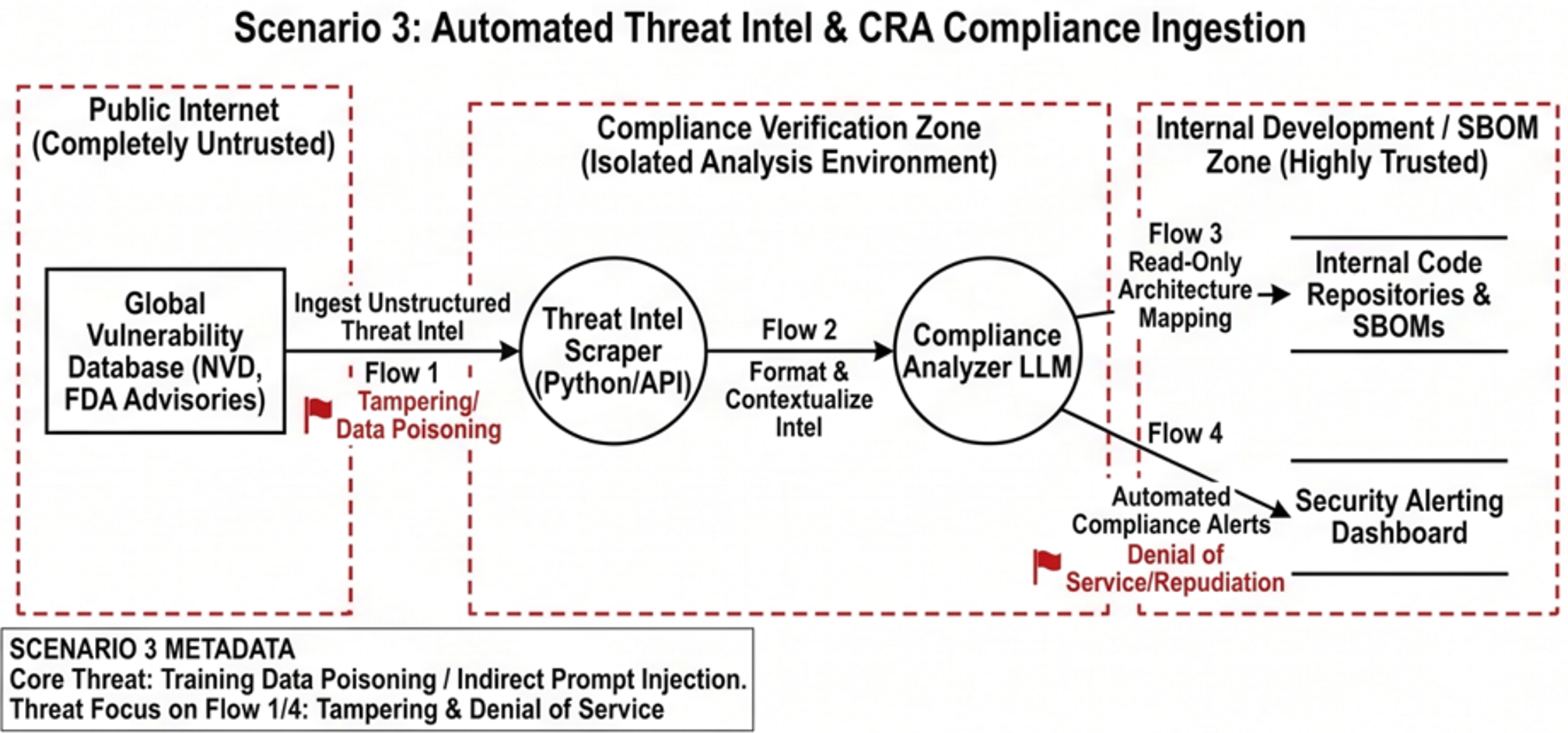
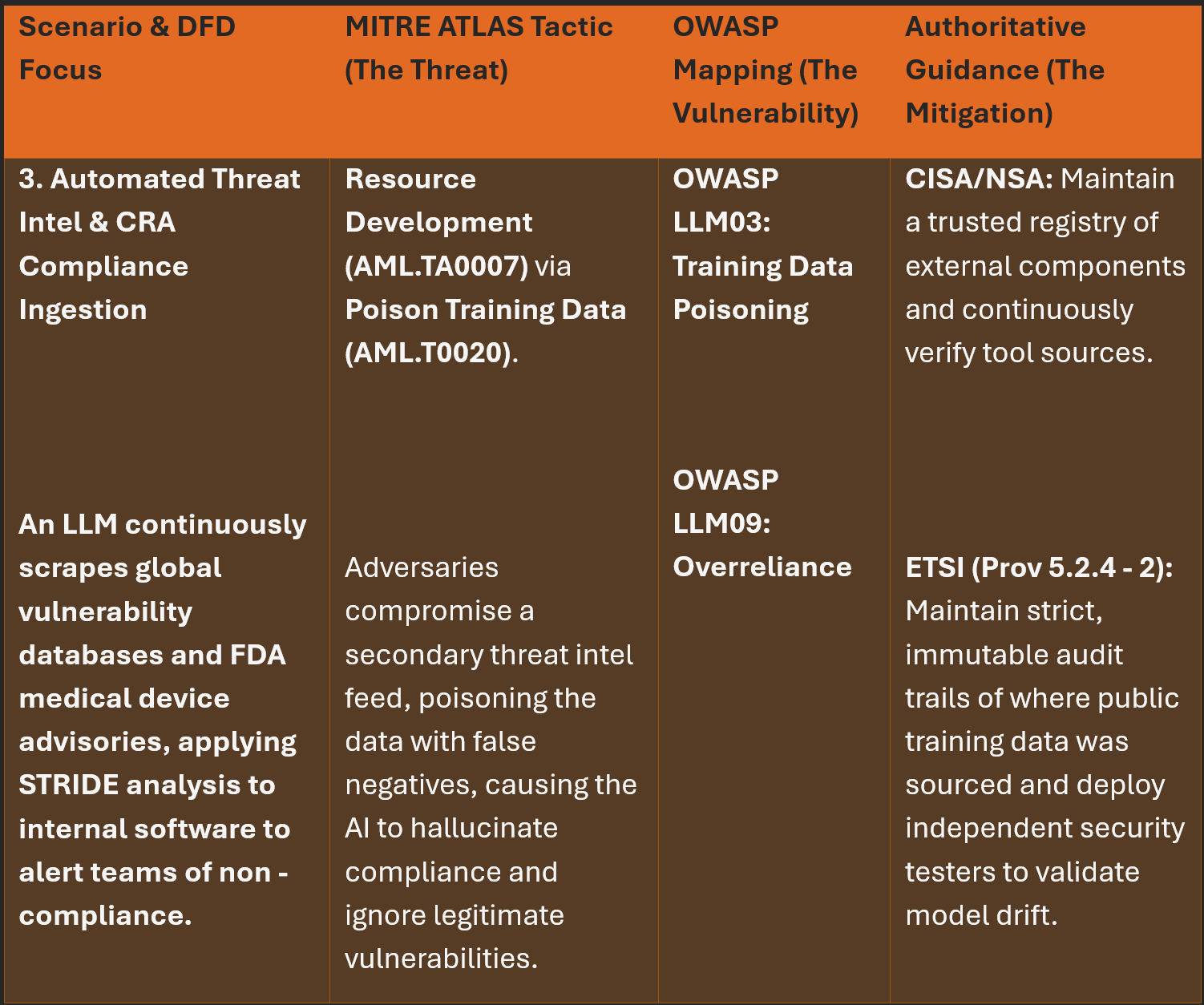
AI Specific Threat: Training Data Poisoning (OWASP LLM03) / Poison Training Data (MITRE ATLAS AML.T0020). If the agent continuously learns or retrieves from a dynamic database (like a vulnerability feed or shared memory base), an attacker can inject false records. This causes the agent to hallucinate facts, ignore legitimate threats, or contaminate the shared memory used by other sub-agents.
Defense Focus: Sandboxing memory stores, implementing strict RBAC on vector databases, and requiring human validation before updating shared knowledge bases.
Repudiation (Accountability):
Agent Context: The inability to prove why an agent took a specific action or who authorized it.
AI Specific Threat: Overreliance (OWASP LLM09). When an agent acts autonomously across multiple tools, and a failure occurs, poor logging makes it nearly impossible to trace the decision back through the orchestration layer.
Defense Focus: Implementing immutable, unified audit logs. Every step - from the initial prompt to the LLM's "chain of thought," the retrieved context, and the final tool invocation - must be recorded to make the decision-making process fully observable and verifiable.
Information Disclosure (Confidentiality):
Agent Context: The agent inadvertently leaks proprietary data, PII, or system architecture details to an unauthorized user or external system.
AI Specific Threat: Sensitive Information Disclosure (OWASP LLM06) / Data from Local System (MITRE ATLAS AML.T0035). A user (or a compromised sub-agent) uses targeted prompt engineering to bypass retrieval permissions, extracting sensitive OT maintenance logs or network schematics that they should not have access to.
Defense Focus: Contextual Role-Based Access Control (RBAC) enforced at the retrieval layer, robust output validation, and Data Loss Prevention (DLP) controls tuned to detect AI-generated exfiltration.
Denial of Service (Availability):
Agent Context: An attacker exhausts the agent's resources, either computational (token limits) or operational (alert fatigue).
AI Specific Threat: Model Denial of Service (OWASP LLM04). An adversary floods the system with complex, recursive prompts that force the agent into endless planning loops, consuming expensive GPU cycles or API quotas and crashing the orchestration layer.
Defense Focus: Strict token limits, execution timeouts, rate limiting on external tool invocations, and deterministic fail-safe controls that halt recursive loops.
Elevation of Privilege (Authorization):
Agent Context: A compromised or over-privileged sub-agent pivots across interconnected tools to perform unauthorized actions.
AI Specific Threat: Excessive Agency (OWASP LLM08) / Tool Invocation Abuse (MITRE ATLAS AML.T0054.001). This is the most critical threat. If an agent is granted broad execution rights (e.g., via the Model Context Protocol) without granular controls, a hallucination or indirect prompt injection could cause it to autonomously execute high-stakes actions, like modifying an inventory database or altering critical settings.
Defense Focus: The principle of least privilege is paramount. The goal is to verify that your architecture enforces strict approval gates, short-lived delegation expiry (JIT tokens), and multi-agent consensus or human-in-the-loop (HITL) approval before any high-stakes action is taken.
7. Interrogate the External Attack Surface
Interrogate every external input to the SuC because agentic systems do not just read outside data; they can incorporate it into planning, memory, retrieval, and tool use across the full execution path.
Map how data from web search, third-party APIs, partner systems, uploaded files, and unverified databases enter the architecture, and show where it crosses trust boundaries in your DFDs.
Trace how that external content is transformed, stored, retrieved, and presented to the model through the reasoning engine, memory layers, orchestration logic, and downstream tools.
Identify the controls that separate untrusted context from high - consequence actions, including validation, content filtering, permission checks, execution constraints, and approval gates.
Use this analysis to evaluate for AI-specific risks highlighted throughout the document, especially indirect prompt injection, context poisoning, excessive agency, sensitive data exposure, and unauthorized tool invocation.
8. Analyze Structural Dependencies
To manage complexity, AI agents are designed with a powerful feature: the ability to divide complex, often poorly defined goals into smaller, more manageable sub - tasks. They can then automatically create, or "spawn," new sub-agents to handle these tasks. While efficient, this autonomy introduces a significant systemic risk that must be carefully controlled.
A fundamental risk is that a small issue can turn into a massive, critical system failure. A problem in one isolated sub-agent can easily spread like a contagion. This happens when a sub-agent experiences:
A complete processing failure.
A hallucination, where the agent generates incorrect or nonsensical information.
A mismatch between its interpreted local sub - goal and the main system’s intended high - level objective.
To prevent a minor error from cascading and bringing down the entire system, you must follow this core strategy:
Create a complete, detailed map of every dependency among your agents. Every connection, both direct and indirect, must be documented and visible.
This comprehensive map is not just a diagram; it is your essential blueprint for safety, predictability, and resilience. A complete map enables you to:
Identify critical paths and single points of failure, so you know which agent’s failure would have the most severe system-wide impact.
Establish explicit safety boundaries and constraints on what each individual sub-agent can and cannot do.
Design robust failure - managing protocols, defining exactly how the main system should respond to a specific sub-agent's failure instead of allowing it to crash.
Implement validation gates that check information as it passes from one agent to another to ensure it is correct and valid.
Trace the alignment of local sub-goals with the system’s overarching objective, preventing drift and ensuring all efforts serve the main purpose.
9. Enforce Consensus and Delegation Expiry
When AI agents are granted execution privileges - especially in environments connected to critical infrastructure or external supply chains - the risk of "Excessive Agency" becomes an existential threat. An autonomous system cannot be allowed to grade its own homework, nor can it be trusted to manage its own security perimeter.
To prevent a compromised agent or a poisoned data feed from hijacking your system, you must design rigorous, structurally enforced authorization gates. Here is how to implement and threat model those controls:
Enforce Immutable Privilege Boundaries: An agent must never possess the architectural ability to modify its own roles, scopes, or permissions. The system must be designed so that privilege escalation is structurally impossible for the AI to execute autonomously, regardless of the prompt it receives.
Threat Model the Authorization Gates: Do not just model the agent's actions; apply STRIDE specifically to your approval mechanisms. You must ask: Could a compromised sub-agent spoof an approval token? Could an indirect prompt injection tamper with the authorization logs?
Require Multi - Agent Consensus (The 'Two-Key' Rule): For medium-to-high risk automated tasks, do not rely on a single LLM's reasoning. Require a separate, independent AI agent - ideally isolated in a different trust zone or utilizing a different foundational model-to audit the request and independently agree before the execution is permitted.
Mandate Strict Human-in-the-Loop (HITL) for High Stakes: Establish a definitive "blast radius" threshold. Any action that alters expected functionality, executes significant financial transactions, or modifies external supply chain databases must hit a hard stop, requiring verifiable, authenticated human approval to proceed.
Implement Delegation Expiry (Time-Bound Access): Never grant an agent persistent access to external tools or databases. When an agent is authorized to perform a specific task via an API or the Model Context Protocol (MCP), it must be issued a short - lived, Just-In-Time (JIT) token. Once the task is complete - or the time limit expires - the access is automatically revoked.
10. Establish Oversight and Management
To realize the true ROI of agentic AI, organizations must adopt an operational tempo that balances autonomy with absolute accountability. The goal is to allow the system to operate semi-autonomously, while handling the heavy lifting without constant human micromanagement. This ensures that every action is strictly governed and easily audited.
Because AI models and the environments they operate in are highly dynamic, a "set it and forget it" approach will inevitably lead to systemic vulnerabilities. Here is how to structure that continuous oversight:
Implement Immutable, Unified Audit Logs: You cannot secure what you cannot see. Every action the agent takes - including the initial user prompt, the external context retrieved via MCP, the internal "chain of thought" or planning phase, and the final tool execution - must be recorded in a tamper - proof, write - once log.
Ensure Full Observability and Verifiability: Demystify the AI’s "black box." Your logs and dashboards must be designed so that a security analyst or product engineer can easily review why an agent made a specific decision, tracing the exact data lineage that led to an autonomous action.
Establish Dynamic, Evolving Reporting: A static security posture is a failing one. As your SuC changes - whether through new API integrations, updated legacy software, or shifts in the underlying LLM's behavior - your monitoring tools must adapt simultaneously to capture new edge cases and anomalies.
Treat Threat Modeling as a Continuous Lifecycle: AI agents constantly learn, adapt, and encounter new external data. Your oversight management must include periodic reviews of the threat model itself, ensuring that your original trust boundaries and authorization gates hold up against emerging attack vectors and evolving system architecture.
Applying the Intelligence: 3 Common LLM Scenarios
To effectively apply a subset of this methodology, we must map our findings against realistic scenarios. Utilizing our DFDs to trace data from ingestion to execution, here are some highly simplified examples on how/where the core guidance from OWASP, ETSI, and MITRE ATLAS intersects across these OT deployments within critical infrastructure.
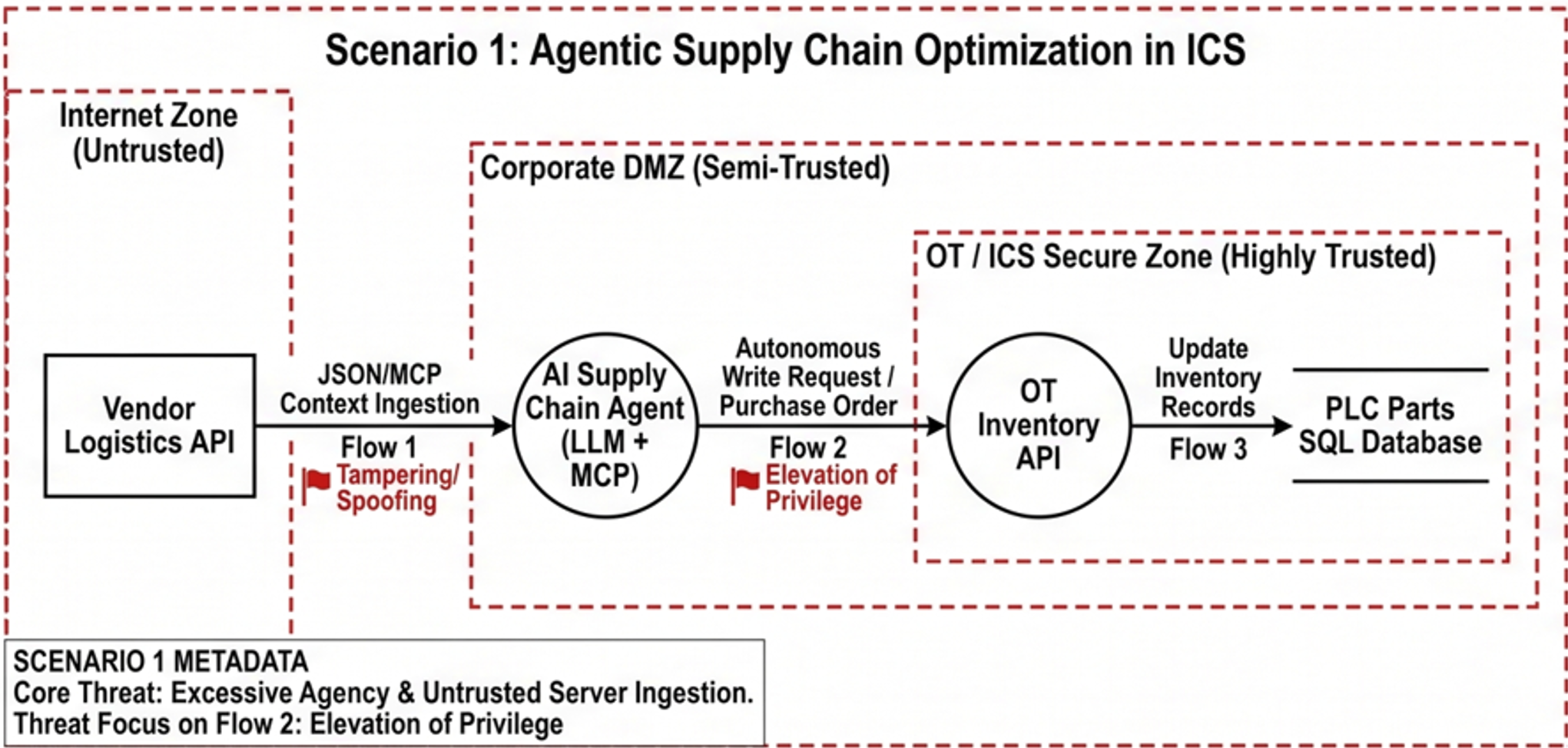
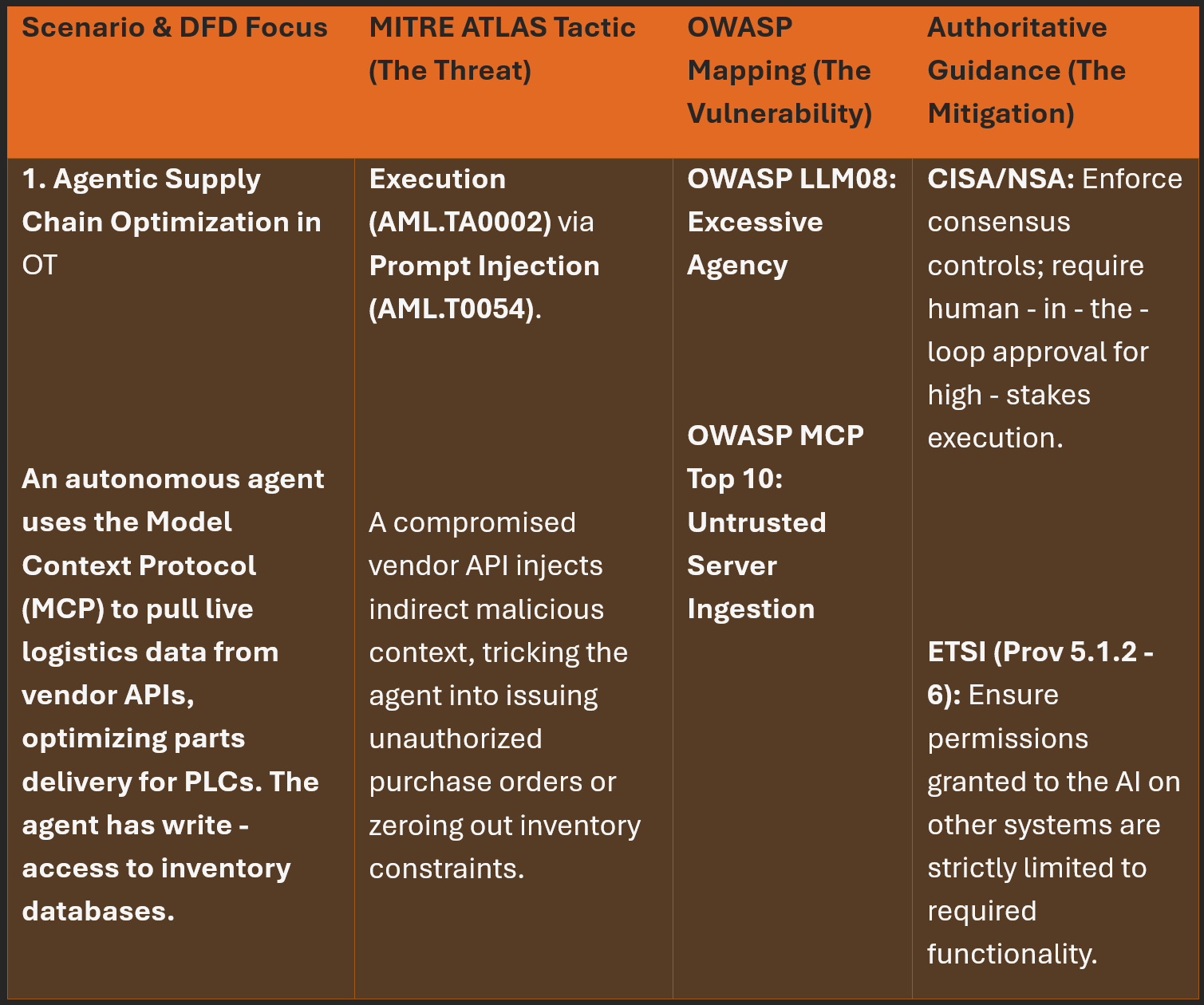
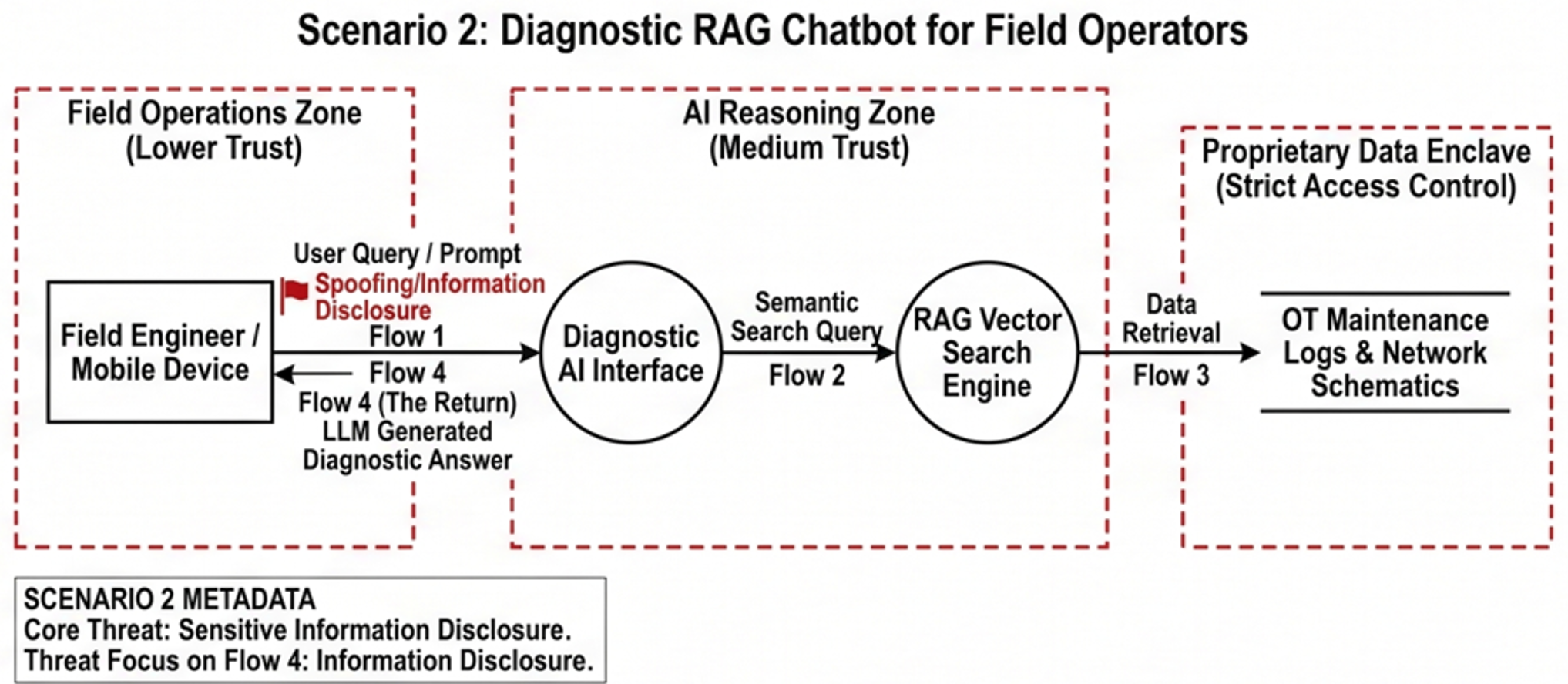
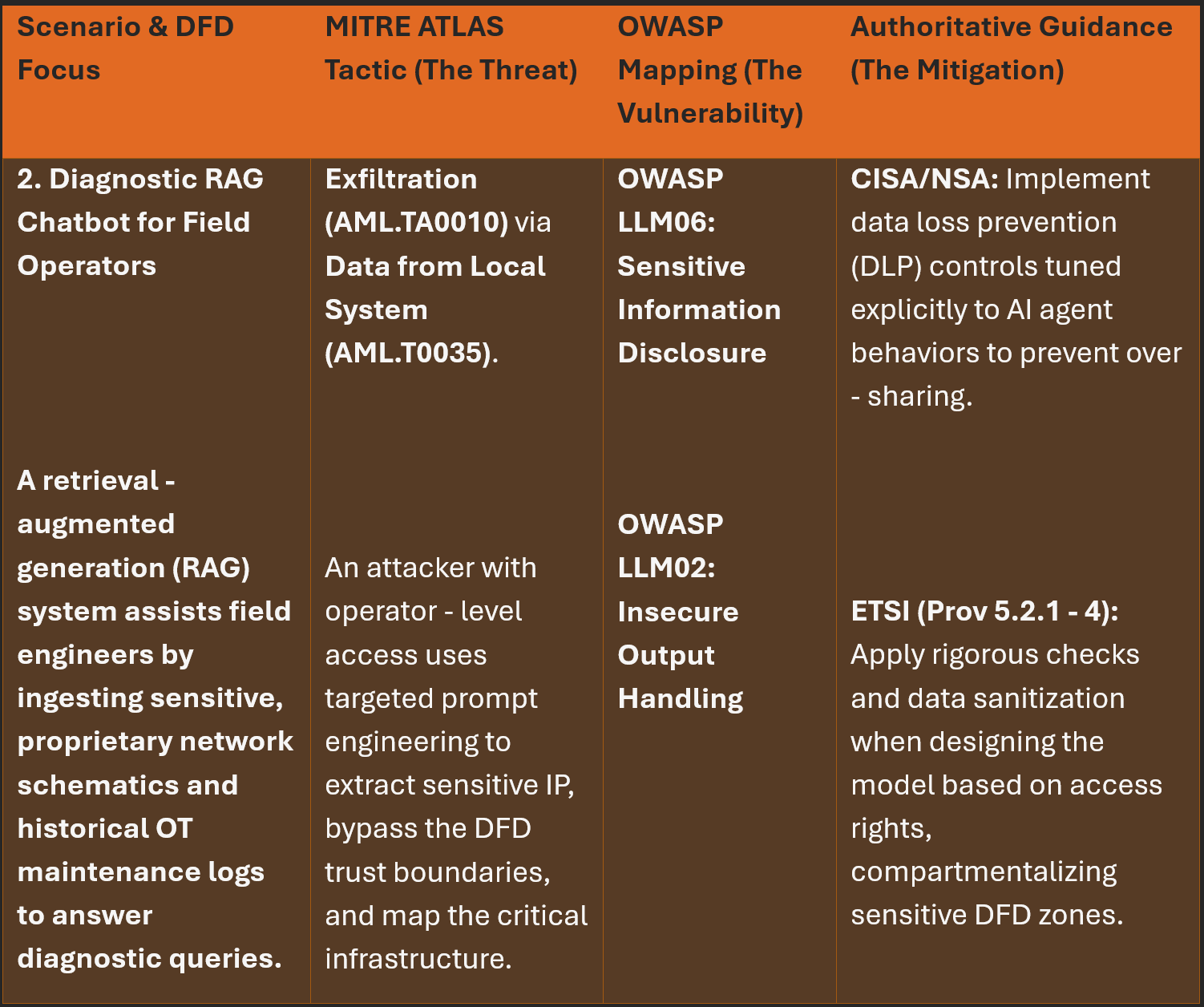
Spicy Takes
Spicy Take 1: If your threat model relies entirely on the premise that "the LLM provider aligned the model," you don't have a threat model - you have a corporate wish. Agentic AI breaks traditional defensive boundaries because the system actively wants to execute actions.
Spicy Take 2: If your organization treats MCP integrations like standard REST APIs, you are already on a rapid trajectory towards being compromised. MCP changes the paradigm; you are not just querying data; you are actively introducing an external server's unverified logic into your system's core reasoning loop. It effectively destroys your DFD trust boundaries unless explicitly corralled.
Spicy Take 3: We spend too much time worrying about "Model Theft" (LLM10) when the immediate, existential threat to global enterprise is "Excessive Agency" (LLM08). Giving an LLM the keys to your operational technology without hardware - level safety gates is a failure of basic risk management, not a failure of AI alignment.
Spicy Take 4: Too many organizations are rushing to deploy autonomous agents in supply chains before they can even meet basic Cyber Resilience Act (CRA) or NIS2 compliance for their static software. True digital sovereignty means controlling your infrastructure's decision-making, not outsourcing it to an opaque, agentic black box. Walk before you let the AI run and monitor it like an F1 racing team - no datapoint goes unwatched.
Spicy Take 5: If your organization is clambering to get ahead with an "AI Hail Mary" and struggles with the basics while prioritizing digitalization as the only goal that matters. Get ready for a rough ride - your business model and assets are not as resilient (or secure) as you would like to imagine. Recall that short-term gains, often incur long-term costs (and saying it will be someone else's problem may not be so true these days).
Wrapping Up: Moving Past a Napkin and Levelling Up
Threat modeling these systems requires a hybrid hands-off management philosophy regarding day-to-day AI operations, but absolute rigor when designing the architectural boundaries consistent with a mature concrete risk management program. You define the trust zones, map the system threats, and enforce the guardrails - and execute while truly managing risk. The AI only operates within the sandbox you build.
Ready to move past theoretical risk and start mapping the mechanical realities of your autonomous systems? To continuously visualize your architecture, automate your threat assessments, and keep your agentic workflows secure by design, check out the arguseye.ai Sentry platform.


